生成模型笔记
生成模型 Generative models
概述
分类
监督 无监督 自监督
无监督 including:
- PCA
- Auto Encoder 学习数据的压缩表示
- 生成任务的模型 自监督 是无监督的一个子集。它不需要标注的数据,能生成伪标签。
生成模型和判别模型
判别式(discriminative):
- 需要 annotation 数据
- 模型需要根据输入的 x 产生标签 y,或者学习输入数据的 latent structure
- 缺点:存在 adversarial attack,不能区分不合理的类别的图像
- Eg. Classification, regression, … 生成式(generative):
- 不需要 annotation 数据
- 根据先验知识(prior)生成不存在的数据
- Eg. GAN, Diffusion, pixelRNN, VAE, Flow…
生成模型的分类
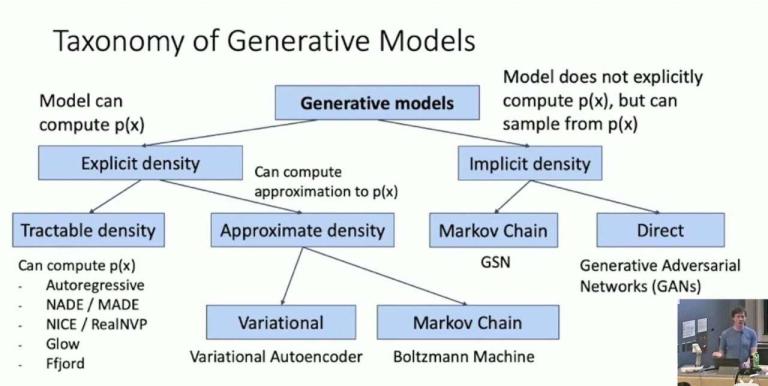 Another:
Another:
- Auto regressive / component by component (eg. PixelRNN)
- Autoencoder
- GAN
- Flow-based model
GAN
目的
用来生成图像数据
原理
由 Generator + Discriminator 两部分组成
Generator:生成新的图像数据
训练目标:\(G = argmin(real\_label, fake\_score)\)
需要让生成图像和真的图像尽可能相像
Discriminator:判别图像的真假(如果生成的图像它都无法分辨了,那么说明可以以假乱真)
训练目标:\(D = argmax(G(z)\_score, real\_label)\)
需要让真的图像和生成图像各自生成的 score 差距尽量大
实现
Generator
[1, noise_dim] => [C, H, W] (image)
(neural network)
class Generator(nn.Module):
"""
Input shape: (batch, in_dim)
Output shape: (batch, 3, 64, 64)
"""
def __init__(self, in_dim, feature_dim=64):
super().__init__()
#input: (batch, 100)
self.l1 = nn.Sequential(
nn.Linear(in_dim, feature_dim * 8 * 4 * 4, bias=False),
nn.BatchNorm1d(feature_dim * 8 * 4 * 4),
nn.ReLU()
)
self.l2 = nn.Sequential(
self.dconv_bn_relu(feature_dim * 8, feature_dim * 4), #(batch, feature_dim * 16, 8, 8)
self.dconv_bn_relu(feature_dim * 4, feature_dim * 2), #(batch, feature_dim * 16, 16, 16)
self.dconv_bn_relu(feature_dim * 2, feature_dim), #(batch, feature_dim * 16, 32, 32)
)
self.l3 = nn.Sequential(
nn.ConvTranspose2d(feature_dim, 3, kernel_size=5, stride=2,
padding=2, output_padding=1, bias=False),
nn.Tanh()
)
self.apply(weights_init)
def dconv_bn_relu(self, in_dim, out_dim):
return nn.Sequential(
nn.ConvTranspose2d(in_dim, out_dim, kernel_size=5, stride=2,
padding=2, output_padding=1, bias=False), #double height and width
nn.BatchNorm2d(out_dim),
nn.ReLU(True)
)
def forward(self, x):
y = self.l1(x)
y = y.view(y.size(0), -1, 4, 4)
y = self.l2(y)
y = self.l3(y)
return y
Discriminator
[C, H, W] => scalar (1x1)
(neural network)
class Discriminator(nn.Module):
"""
Input shape: (batch, 3, 64, 64)
Output shape: (batch)
"""
def __init__(self, in_dim, feature_dim=64):
super(Discriminator, self).__init__()
#input: (batch, 3, 64, 64)
"""
NOTE FOR SETTING DISCRIMINATOR:
Remove last sigmoid layer for WGAN
"""
self.l1 = nn.Sequential(
nn.Conv2d(in_dim, feature_dim, kernel_size=4, stride=2, padding=1), #(batch, 3, 32, 32)
nn.LeakyReLU(0.2),
self.conv_bn_lrelu(feature_dim, feature_dim * 2), #(batch, 3, 16, 16)
self.conv_bn_lrelu(feature_dim * 2, feature_dim * 4), #(batch, 3, 8, 8)
self.conv_bn_lrelu(feature_dim * 4, feature_dim * 8), #(batch, 3, 4, 4)
nn.Conv2d(feature_dim * 8, 1, kernel_size=4, stride=1, padding=0),
nn.Sigmoid()
)
self.apply(weights_init)
def conv_bn_lrelu(self, in_dim, out_dim):
"""
NOTE FOR SETTING DISCRIMINATOR:
You can't use nn.Batchnorm for WGAN-GP
Use nn.InstanceNorm2d instead
"""
return nn.Sequential(
nn.Conv2d(in_dim, out_dim, 4, 2, 1),
nn.BatchNorm2d(out_dim),
nn.LeakyReLU(0.2),
)
def forward(self, x):
y = self.l1(x)
y = y.view(-1)
return y
训练
D
z: 初始化一个 shape 为 [batch_size, noise_dim] 的噪声
fake_img = G(z)
real_img = img
fake_label = [0 for _ in range(batch_size)]
real_label = [1 for _ in range(batch_size)]
fake_score = D(fake_img)
real_score = D(real_img)
fake_loss = LossFunction(fake_label, fake_score)
real_loss = LossFunction(real_label, real_score)
Loss = (fake_loss + real_loss) / 2
Loss.backward()
...
先固定 G 的参数,多次训练 D 使得 D 的 loss 最小,然后再训练 G。
G
loss = LossFunction(real_label, fake_score)
loss.backward()
...
Auto Encoder 和 VAE
Auto Encoder
结构
Encoder:
Input data (img, text,..) => embedding
Decoder:
embedding => output data
作用
- 学习数据的压缩表示
- 方便在中间对数据做一些操作(融合信息等)
训练
- Loss function:\((x - X)^2\),无需标签
- 同时训练 encoder 和 decoder 的参数
VAE
- KL 散度:公式有点类似交叉熵,用来 measure 2 个分布的差异(但要已知分布表达式)
原理
https://spaces.ac.cn/archives/5253
- 目标——理想的生成模型:给定一个采样的数据分布,你可以根据这个数据集知道数据的分布,便于之后生成其他样本。然而几乎不可能做到。
- 根据 \(P(x)=\sum_zP(x|z)P(z)\) ,如果知道了后两者的分布,那么就能知道 x 的分布
- 假设分布\(P(z|x)\)服从正态分布,由 \(P(z)=\sum_xP(z|x)P(x)\) \(=P(z|x)\sum_xP(x)\) \(=P(z|x)\)
知先验分布 P(z) 服从正态分布
- 那么从输入 x 可拟合出 n 个正态分布函数,采样得到 z
- 现在再用神经网络拟合一个从 z 到 x_观测值的函数
整体 pipeline 如下图所示

- Loss function = loss(x, x_观测值) + KL散度(分布i, 标准正态分布)
这里之所以要限制成标准正态分布的原因是,如果不加以约束,模型会倾向于学到趋于0的方差,那么噪声不复存在,采样就没有意义了;而标准正态分布的方差 != 0
Code
https://zhuanlan.zhihu.com/p/452743042
Diffusion Model(DDPM)
- DDPM:是一种特殊的扩散模型
原理
前向过程:加噪
- 需要在每个 step 中向图片中加入随机采样的高斯噪声(为什么是高斯噪声?:无穷多的任意分布的样本最后的分布都会趋于正态分布)
有一个重参数化的技巧,可以简化采样的步骤:
\(x_t\) 的计算公式为: \(x_t=\sqrt{\bar{\alpha}_t}x_0+\sqrt{1-\bar{\alpha}_t}\epsilon\), 其中 \(\bar{\alpha}_t=\alpha_1\alpha_2\ldots\alpha_t\),
只需要采样一次,就可以生成 step-t 的图像
-
推导:


-
不需要训练参数,前向过程只是一个给定超参数 \(\beta_t\) 可以自动求得加噪后的图像的过程
反向过程:去噪 & 生成
- 目标是逐渐去除噪声,恢复原图像
-
推导:

-
需要训练的参数为 生成噪声的网络参数
- 完整推导:
 根据这个推导,可以从 \(x_t\) 时刻得到加噪前的状态 \(x_{t-1}\),这样一步步推回 \(x_0\) 状态,生成原始图像
根据这个推导,可以从 \(x_t\) 时刻得到加噪前的状态 \(x_{t-1}\),这样一步步推回 \(x_0\) 状态,生成原始图像
训练 & 推理步骤
- 对每个训练样本 \(x_0\),随机采样时间步 t 和噪声 ϵ,计算出带噪声的图像
- 训练预测噪声的网络:输入 \(x_t\) 和 t,输出预测的噪声 ϵ
- 计算噪声的真实值和预测值的 MSE,反向传播以优化网络参数
- 推理 就是逐步对初始噪声 \(x_t\) 逐步应用反向传播过程生成 \(x_0\)
注意
β 的值随着 t 的增加逐渐趋向 1,所以 α 随着 t 的增加逐渐趋向 0.
可得 x_t 逐渐趋向于 噪声e。
所以可认为,任意一张正态分布的噪声都可当作 t 时刻加噪后的图像
Flow-based Model
https://zhuanlan.zhihu.com/p/59615785
原理大致是,能根据 已知分布 和 未知分布与已知分布的关系,求出未知分布。 未知分布存在一般表达式,通过神经网络去学习参数。