NeRF:原理篇
一篇文章清楚如何从 图片数据集 得到 最终视频。
前置知识
NeRF 曾获得 ECCV2020 Best Paper Honorable Mention.
其核心是使用二维图像隐式重建三维场景,可以根据静态场景渲染出任意角度的清晰图像。
pipeline如图所示:
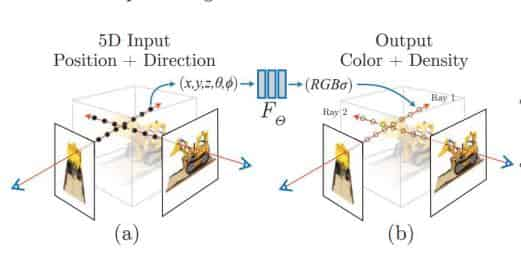
了解了 NeRF 能从输入 (\(x,y,z, \theta, \phi\)) 通过神经网络映射到 (\(\sigma, RGB\)),但其实还有很多细节不清楚:
-
从上传图片数据集开始,图片是二维的数据,是怎么产生三维格式的输入,又是如何得到表示方向的量的呢?
-
怎么从网络的输出得到最后展示出来的视频的?
-
这个模型是怎么样训练的?损失函数是什么,如何优化?
-
原文中提到的 Positional encoding 位置编码 和 粗采样细采样 具体是如何做的?
接下来我将对这些问题一一介绍
数据处理
COLMAP
首先需要上传一组照片,通过 COLMAP库 可得到:
-
camara.txt 相机内参(从相机坐标系(三维)到二维图像的转换)
-
images.txt 相机外参 (完成从相机坐标系到世界坐标系的转换)
-
points3D.txt 特征点(三维)的坐标
通过 COLMAP 可以知道相机的内外参数,那么可以把 二维图像坐标 依次转成 相机坐标系下三维坐标 世界坐标系下三维坐标,就得到了神经网络的输入(x,y,z)
poses_bound.npy 文件
poses_bound.npy 是一个 shape 为 (N, 17) 的矩阵 (N 为输入的图片数量)
17 = 3 * 3 (相机外参 旋转矩阵R) + 3 (相机外参 平移向量K) + 3 (图片的 H W, 相机的焦距 f, cx cy 可用 H/2 W/2 近似) + 2 (最近和最远采样点的距离)
上述参数在 相机内外参介绍 这篇文章中被介绍到了
利用上一步得到的文件,这一步通过 imgs2poses.py 做了从 COLMAP 到 LLFF 坐标系的转换、求所有相机在世界坐标系下的坐标
射线的表示
引入射线模型是便于后续的采样、渲染。
由上一步知道了每个相机在世界坐标系下的位置,因为两点确定一条射线,所以可以知道从一个相机出发到达每一个像素点的射线
射线的方向是 (\(\frac{x - c_x}{f}, \frac{y - c_y}{f}, 1\))
由这个射线方向也就有了神经网络的输入方向 (\(\theta, \phi\))
模型训练
Loss = \(\sum(C_c(r) - C(r)) ^ 2 + \sum(C_f(r) - C(r)) ^ 2\)
标签值是RGB,Loss 表示粗采样下和细采样下 RGB 的差值的平方之和
粗采样
场景中 (400,400) 个点选择 512 个像素点,有了 512 条射线
每条射线线性均匀采样 32 个点
现在得到了 (512, 32, 3) 的采样数据
Q:如果采样点不位于像素点上怎么办?(就没办法使用像素点的体素密度和颜色属性)
A:实际情况是大多数点可能都不位于像素点上。可采用插值的方法获取邻近点的属性。
位置编码 positional encoding
由于神经网络倾向于表示低频率的结果,所以对于神经网络的一个输入 (x, d), 对于 x 和 d 分别进行位置编码(通过 embedding 把数据变成高频的)
x:3x10x2+3=63 (dim) tensor 的 shape 变成 512x3x63 d:3x4x2+3=27 (dim) tensor 的 shape 变成 512x3x27
细采样
经过粗采样之后得到了采样点的 \(\sigma, RGB, weights..\) 值,weights 在这里用于对采样点进行加权,根据每个点的透明度,为最终的颜色、深度、视差和权重之和进行合成。这种权重计算方式使得对于不透明的点,其权重较大,对结果的贡献较大
对这些权重大的点的射线上的区域进行二次采样,然后再计算一次 \(\sigma, RGB\) 值
渲染
给定任意的 输入视角和点的坐标 可以产生它的颜色,那么就能获得任意视角下的图片。
视频的产生
产生一个相机轨迹,连接通过这个轨迹产生的图片就得到了视频。